01 · Overview: Data → Forward → Loss → Sample in 30 Seconds
By the end of this page you’ll have watched a 4,000-dial machine read
half-finished names like ann… and place its bets on every possible next
letter — then learn from its mistakes, then invent names nobody has ever
had. The entire rest of the tutorial just zooms into the boxes you meet
here.
Before you dive in. This lesson leans on three ideas from 00 · Foundations: the model is a function with adjustable dials (§1), characters become numbers called tokens (§2), and softmax turns raw scores into probabilities (§5). One extra: the loss uses
-log p— all you need to know is that it’s a penalty that is small when the model gave the true answer a high probability, and huge when the model was confidently wrong. Stuck on a word? Open the Glossary.
Theory
A language model is four things in a trenchcoat: a tokenizer, a forward pass, a loss, and a sampler. Everything else — attention, MLPs, rotary embeddings, mixture-of-experts — is just a fancier forward pass.
This whole lesson fits in one sentence:
The model reads a few characters, predicts a distribution over what should come next, and learns by comparing its prediction to the truth.
Three views of that loop — each is a mode you can drive in the sandbox below. Every clip shows the same pipeline: input characters → the MODEL → a probability for each possible next character.
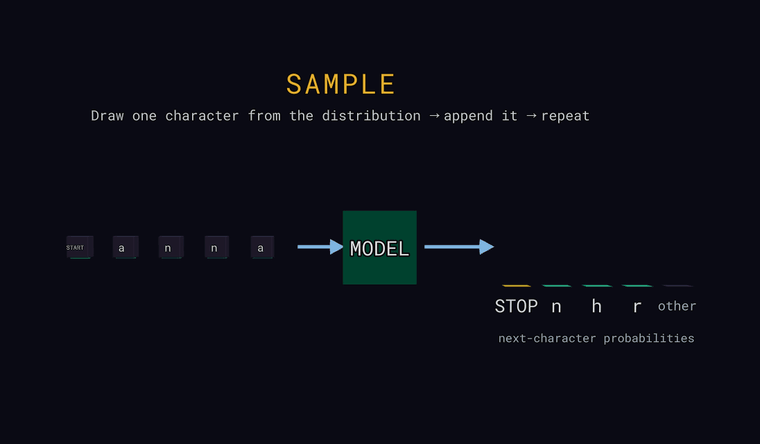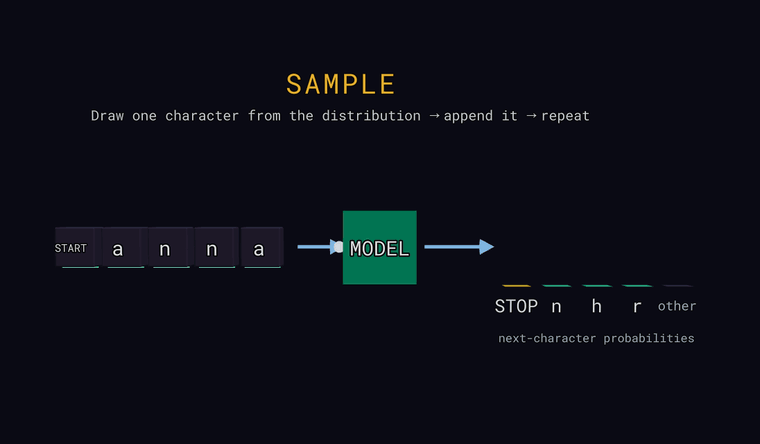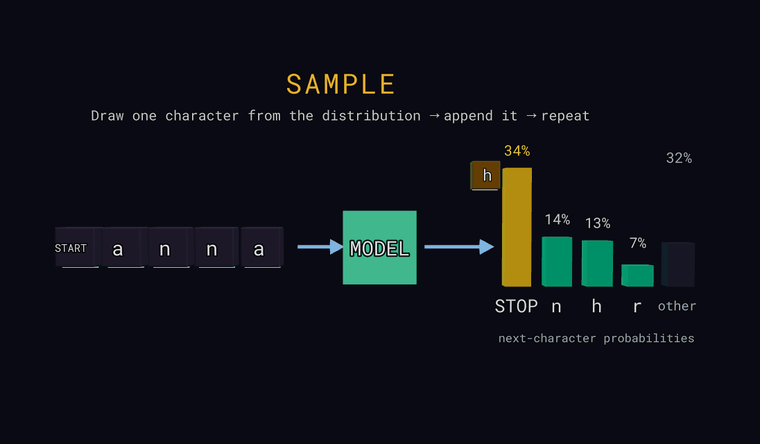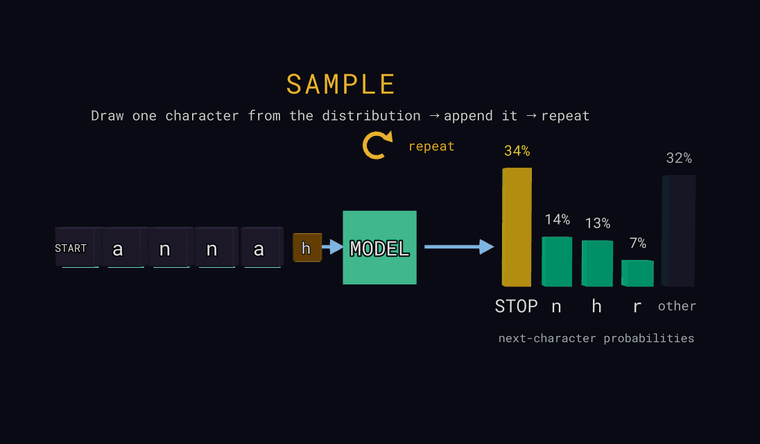
Forward — the model reads the characters and predicts a probability for every possible next character. The bars on the right are that distribution: the most likely few, plus a neutral other bar that is the combined probability of all characters not shown individually (a sum, not a single candidate). One special token is a sentinel: at the very start of the input it means START, and when the model predicts it as the next character it means STOP — end of text. The point: the model outputs a distribution, not a single answer.
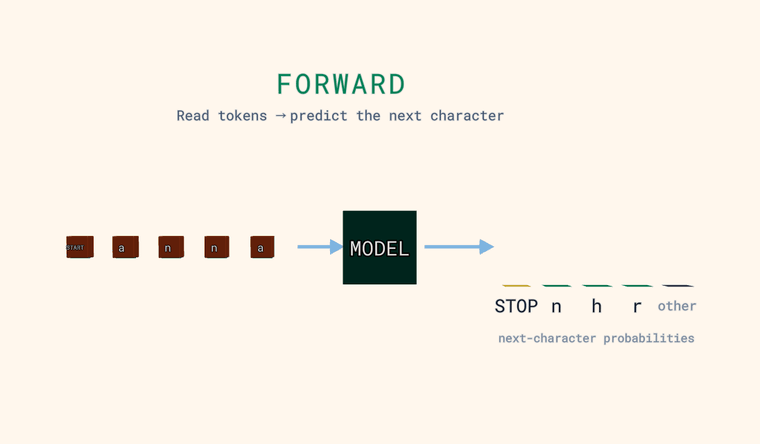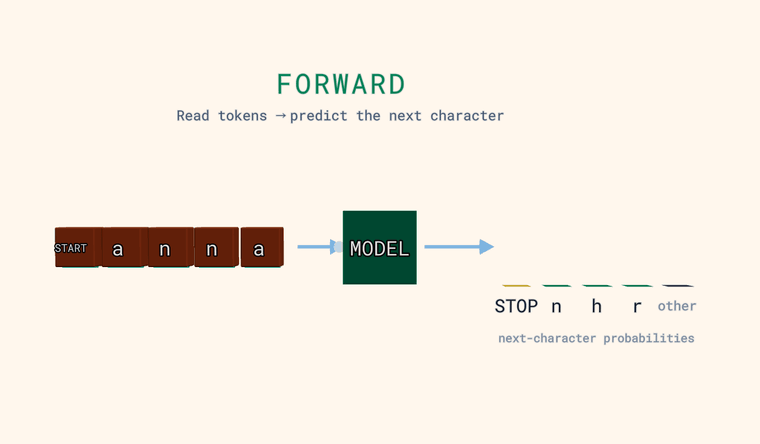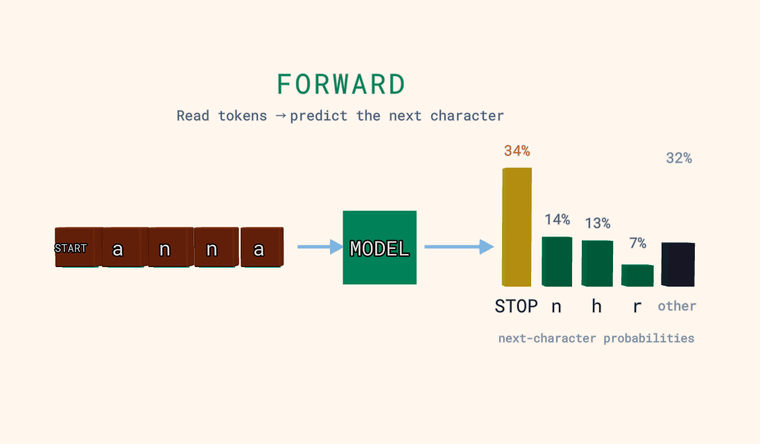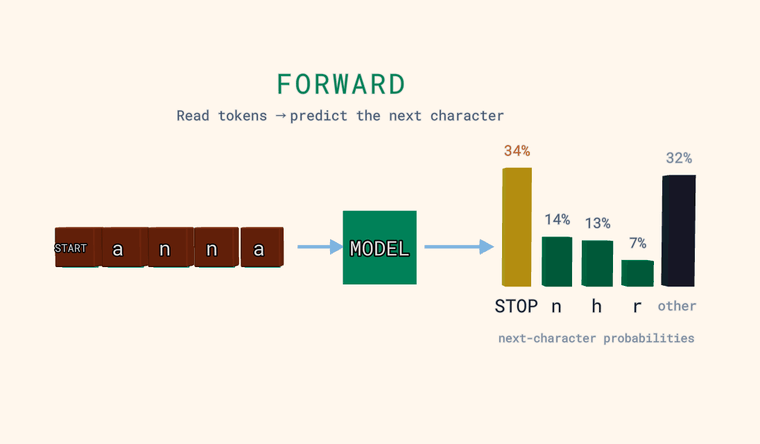
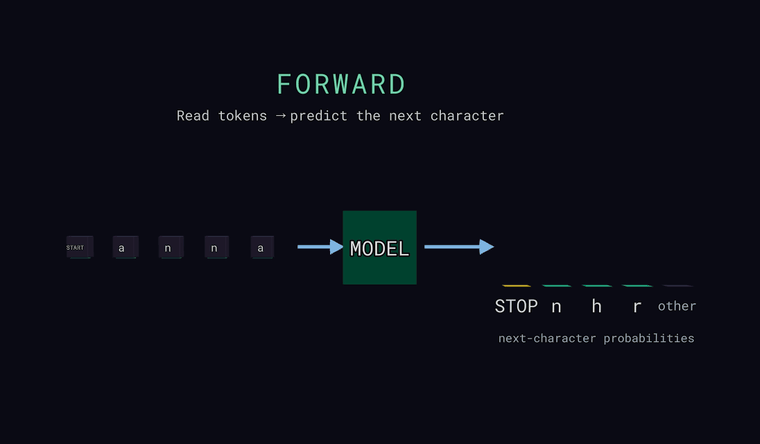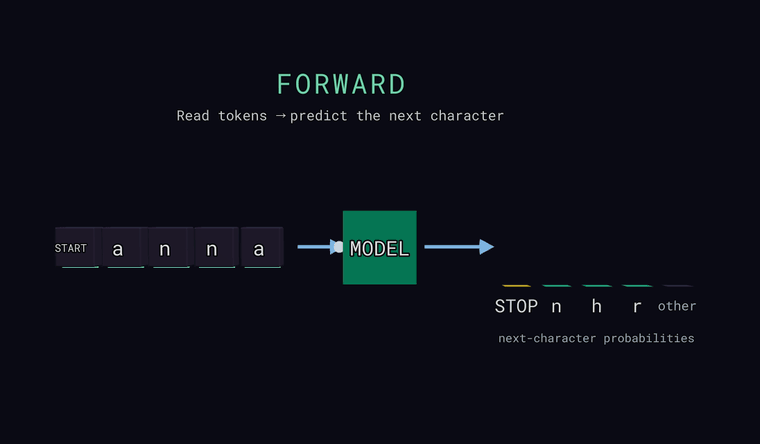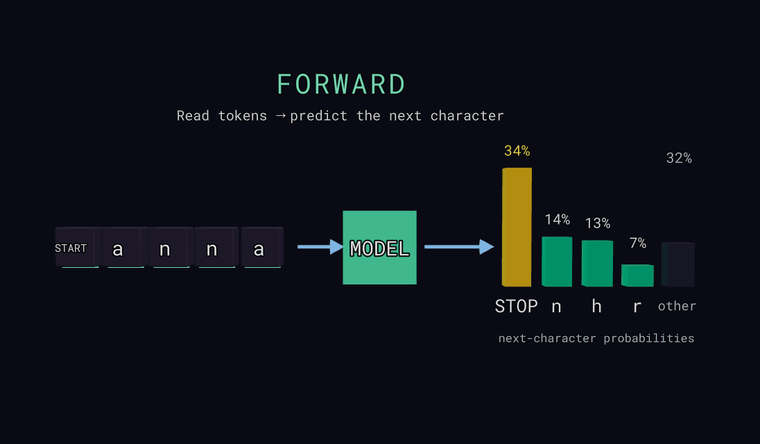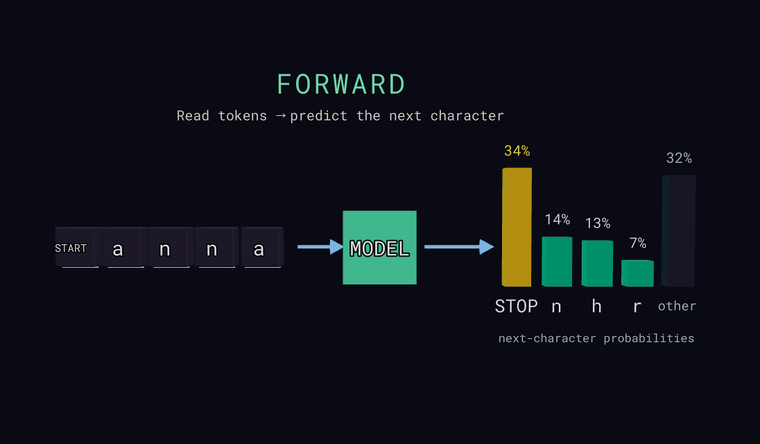
Loss — for each position the model predicts the next character, and we compare that to the true next character. A green check means its top guess was right, a red cross means it was wrong — but the loss itself is the negative log of the probability the model gave to the truth, -log p(true), averaged over positions. So loss depends on the probability of the truth, not just whether the top guess matched.


Sample — at the last position, draw one character at random according to the probabilities (not always the most likely one), append it to the input, and repeat to generate text. If the draw lands in the other bar, the actual hidden character is appended; if it draws the STOP sentinel, generation ends.

The 02 lesson zooms into the autograd that makes “learn from loss” possible. The 03 lesson zooms into the self-attention block. This one keeps the bird’s-eye view.
Annotated Code
The forward pass uses three helpers — linear, softmax, rmsnorm — and one big function gpt() that wires them up. The helpers live in src/microgpt_annotated.py, subsection overview-pipeline-helpers:
def linear(x, w):
return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]
def softmax(logits):
max_val = max(val.data for val in logits)
exps = [(val - max_val).exp() for val in logits]
total = sum(exps)
return [e / total for e in exps]
def rmsnorm(x):
ms = sum(xi * xi for xi in x) / len(x)
scale = (ms + 1e-5) ** -0.5
return [xi * scale for xi in x]The training step (subsection overview-training-step) is just: forward → compute loss against the truth → loss.backward() → an Adam update (with linear learning-rate decay) on every parameter — the optimizer is the subject of 05 · Training & Generation. The TypeScript port in src/inference/{model,value,weights}.ts implements the same forward path so this sandbox can run it live in your browser, on the actual ~89 KB of trained weights checked into the repo.
Sandbox
Type up to 10 characters (or pick a preset). Switch modes: Forward shows the predicted probability for the next character; Loss compares each prediction to the true next character; Sample draws one character from the last-position distribution and appends it.
Try this.
- Type
annin Forward mode. The model has seen a lot of names — isaits top bet for the next letter? How much probability does it giveSTOP?- Now type something deeply un-namelike, like
xqz. Watch the distribution flatten: the model is telling you “I have no idea”, with numbers.- Switch to Loss mode with a real name. Find a position with a red cross where the truth still had decent probability — that’s the difference between “top guess wrong” and “high loss”.
- In Sample mode, resample several times from the same prefix. Same input, different outputs — that’s sampling from a distribution rather than picking the maximum.