01 · Ülevaade: andmed → edasisuund → kadu → valimine 30 sekundiga
Selle lehe lõpuks oled näinud, kuidas 4000 nupuga masin loeb pooleldi
kirjutatud nimesid nagu ann… ja paneb panuse igale võimalikule järgmisele
tähele — seejärel õpib oma vigadest ja mõtleb lõpuks välja nimesid, mida
pole kunagi kellelgi olnud. Kogu ülejäänud õpik lihtsalt suumib sisse
kastidesse, millega siin kohtud.
Enne sukeldumist. See õppetund toetub kolmele ideele lehelt 00 · Alusmõisted: mudel on funktsioon keeratavate nuppudega (§1), tähemärkidest saavad arvud nimega tokenid (§2) ja softmax muudab toored skoorid tõenäosusteks (§5). Üks lisand: kaofunktsioon kasutab
-log p— kõik, mida pead teadma, on see, et tegu on trahviga, mis on väike, kui mudel andis õigele vastusele suure tõenäosuse, ja hiiglaslik, kui mudel eksis enesekindlalt. Jäid mõne sõna taha kinni? Ava Sõnastik.
Teooria
Keelemudel on neli asja ühe vihmamantli all: tokeniseerija, edasisuund (forward pass), kaofunktsioon (loss) ja valija (sampler). Kõik muu — tähelepanu, MLP-d, pöörlevad vektoresitused, ekspertide segud — on lihtsalt uhkem edasisuund.
Kogu see õppetund mahub ühte lausesse:
Mudel loeb mõned tähemärgid, ennustab jaotuse selle üle, mis peaks tulema järgmiseks, ja õpib, võrreldes oma ennustust tõega.
Kolm vaadet sellele tsüklile — igaüks on režiim, mida saad allolevas liivakastis ise juhtida. Iga klipp näitab sama konveierit: sisendtähemärgid → MUDEL (MODEL) → tõenäosus iga võimaliku järgmise tähemärgi kohta.
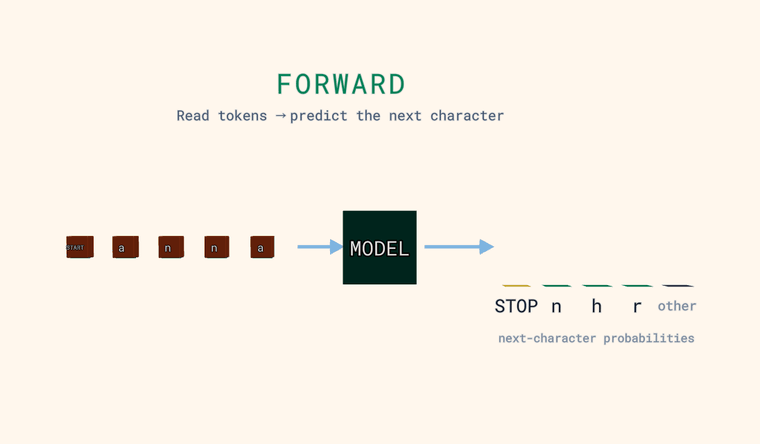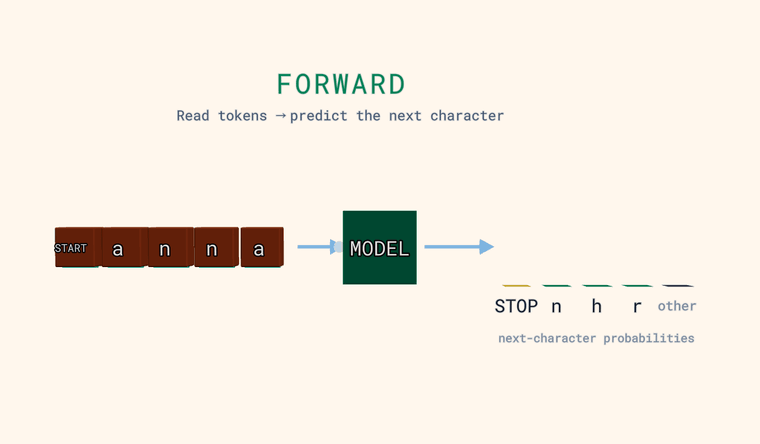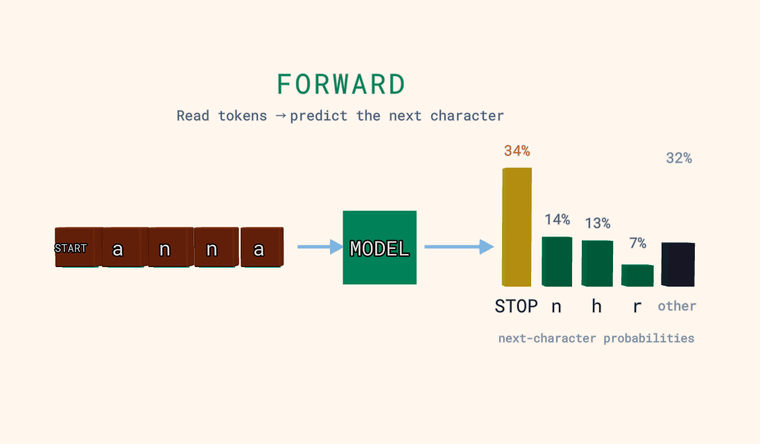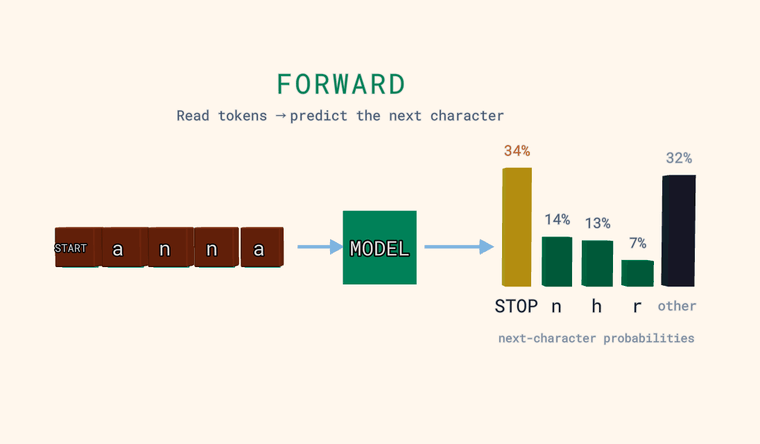
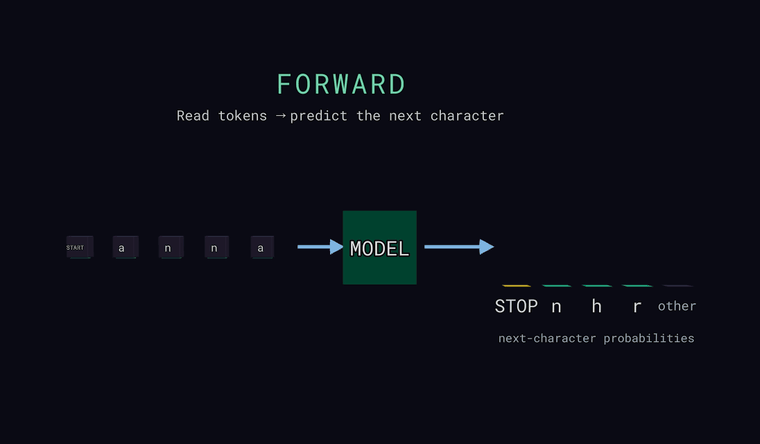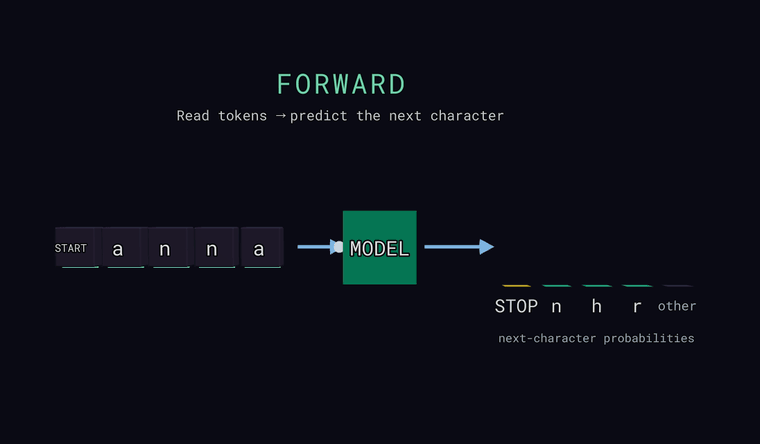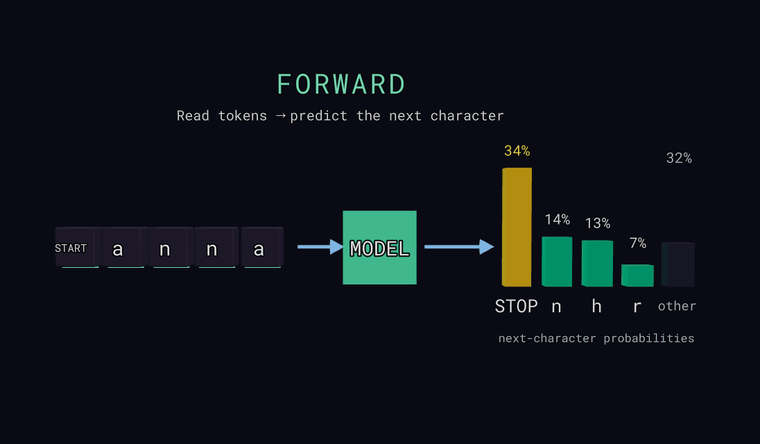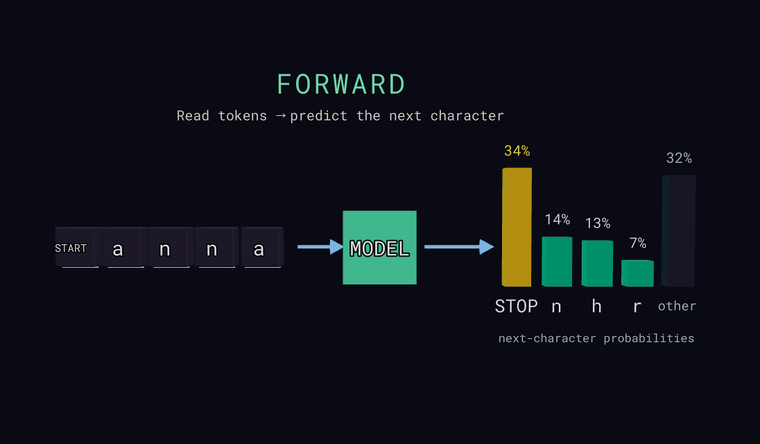
Forward — mudel loeb tähemärgid ja ennustab tõenäosuse iga võimaliku
järgmise tähemärgi kohta. Parempoolsed tulbad ongi see jaotus: mõned kõige
tõenäolisemad, pluss neutraalne tulp other, mis on kõigi eraldi näitamata
tähemärkide summaarne tõenäosus (summa, mitte üks kandidaat). Üks
spetsiaalne token on vahimärk (sentinel): sisendi kõige alguses tähendab see START,
ja kui mudel ennustab seda järgmise tähemärgina, tähendab see STOP —
teksti lõpp. Iva: mudel väljastab jaotuse, mitte üheainsa vastuse.
Loss — igal positsioonil ennustab mudel järgmise tähemärgi ja me võrdleme
seda tegeliku järgmise tähemärgiga. Roheline linnuke tähendab, et mudeli
esipakkumine oli õige, punane rist tähendab, et see oli vale — aga kadu ise
on negatiivne logaritm tõenäosusest, mille mudel andis tõele,
-log p(true), keskmistatuna üle positsioonide. Niisiis sõltub kadu tõe
tõenäosusest, mitte ainult sellest, kas esipakkumine läks täppi.


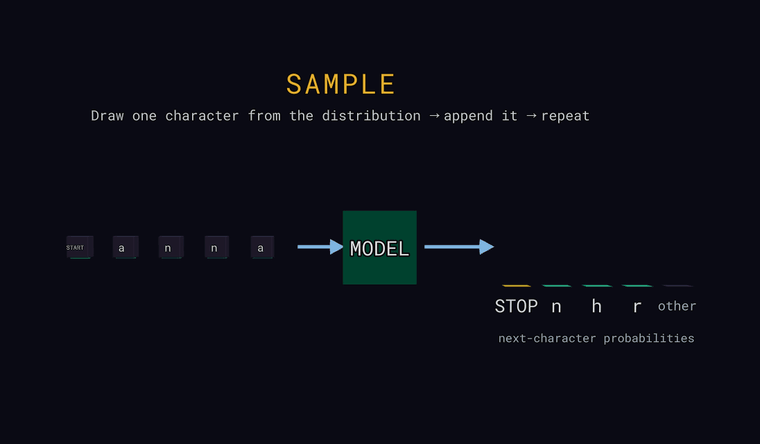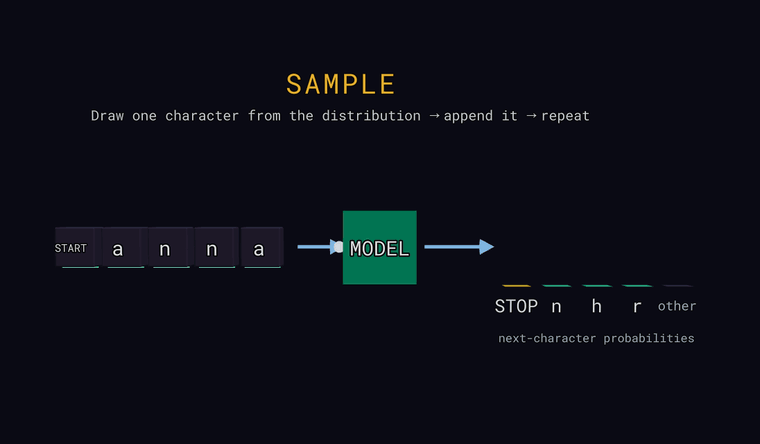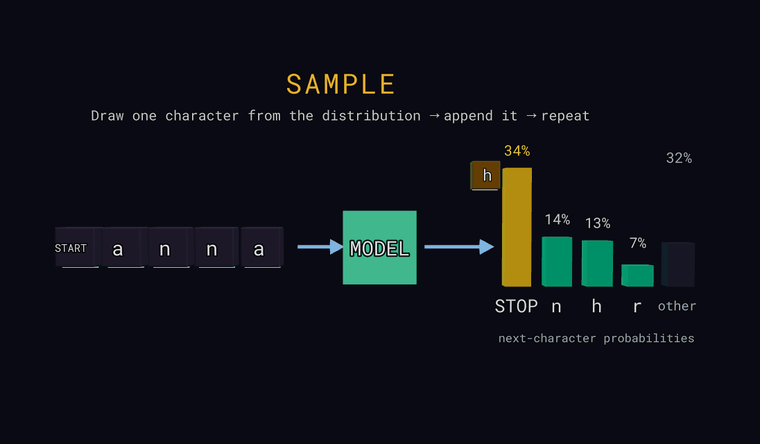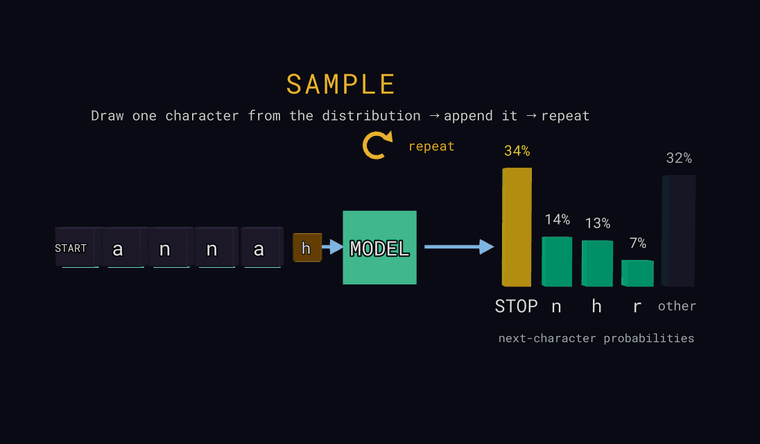
Sample — viimasel positsioonil loosi üks tähemärk juhuslikult vastavalt
tõenäosustele (mitte alati kõige tõenäolisem), lisa see sisendi lõppu ja
korda, et genereerida teksti. Kui loos langeb tulpa other, lisatakse
tegelik peidetud tähemärk; kui loositakse vahimärk STOP, genereerimine
lõpeb.

Õppetund 02 suumib sisse autogradi, mis teeb „kaost õppimise” võimalikuks. Õppetund 03 suumib sisse enesetähelepanu (self-attention) plokki. See õppetund jääb linnulennuvaate juurde.
Kommenteeritud kood
Edasisuund kasutab kolme abifunktsiooni — linear, softmax, rmsnorm —
ja ühte suurt funktsiooni gpt(), mis need kokku ühendab. Abifunktsioonid
elavad failis src/microgpt_annotated.py, alajaotises
overview-pipeline-helpers:
def linear(x, w):
return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]
def softmax(logits):
max_val = max(val.data for val in logits)
exps = [(val - max_val).exp() for val in logits]
total = sum(exps)
return [e / total for e in exps]
def rmsnorm(x):
ms = sum(xi * xi for xi in x) / len(x)
scale = (ms + 1e-5) ** -0.5
return [xi * scale for xi in x]Treeningsamm (alajaotis overview-training-step) on lihtsalt: edasisuund →
kao arvutamine võrdluses tõega → loss.backward() → Adam-uuendus
(õpisammu lineaarse kahanemisega) igal parameetril — optimeerija on õppetunni
05 · Treenimine ja genereerimine teema. TypeScripti
port failides src/inference/{model,value,weights}.ts teostab sama
edasisuuna, nii et see liivakast saab seda jooksutada otse sinu brauseris,
päris ~89 KB treenitud kaaludel, mis on repos kaasas.
Liivakast
Trüki kuni 10 tähemärki (või vali eelseadistus). Vaheta režiime: Forward näitab järgmise tähemärgi ennustatud tõenäosust; Loss võrdleb iga ennustust tegeliku järgmise tähemärgiga; Sample loosib viimase positsiooni jaotusest ühe tähemärgi ja lisab selle lõppu.
Proovi ise.
- Trüki režiimis Forward
ann. Mudel on näinud palju nimesid — kasaon tema esipakkumine järgmiseks täheks? Kui suure tõenäosuse annab taSTOP-ile?- Nüüd trüki midagi sügavalt nimevõõrast, näiteks
xqz. Vaata, kuidas jaotus lamenedes laiali valgub: mudel ütleb sulle arvudega „mul pole õrna aimugi”.- Lülitu režiimi Loss ja kasuta päris nime. Leia positsioon punase ristiga, kus tõel oli siiski korralik tõenäosus — see ongi vahe „esipakkumine vale” ja „suur kadu” vahel.
- Loosi režiimis Sample sama algusjadaga mitu korda uuesti. Sama sisend, erinevad väljundid — see ongi jaotusest valimine, mitte maksimumi võtmine.