01 · Обзор: данные → прямой проход → потери → сэмпл за 30 секунд
К концу этой страницы ты увидишь, как машина с 4 000 ручек читает
недописанные имена вроде ann… и делает ставки на каждую возможную
следующую букву — потом учится на своих ошибках, а потом придумывает имена,
которых ни у кого никогда не было. Весь остальной туториал просто
приближает камеру к коробкам, с которыми ты познакомишься здесь.
Прежде чем нырнуть. Этот урок опирается на три идеи из 00 · Основы: модель — это функция с настраиваемыми ручками (§1), символы становятся числами — токенами (§2), а софтмакс превращает сырые оценки в вероятности (§5). Одно дополнение: функция потерь (loss) использует
-log p— всё, что нужно знать: это штраф, маленький, когда модель дала правильному ответу высокую вероятность, и огромный, когда модель была уверенно неправа. Застрял на слове? Открой Глоссарий.
Теория
Языковая модель — это четыре механизма в одном плаще: токенизатор, прямой проход (forward pass), функция потерь и сэмплер. Всё остальное — внимание, MLP, поворотные эмбеддинги, mixture-of-experts — лишь более навороченный прямой проход.
Весь этот урок помещается в одно предложение:
Модель читает несколько символов, предсказывает распределение того, что должно идти дальше, и учится, сравнивая своё предсказание с истиной.
Три взгляда на этот цикл — и каждый из них режим, которым ты управляешь в песочнице ниже. Каждый клип показывает один и тот же конвейер: входные символы → МОДЕЛЬ → вероятность для каждого возможного следующего символа.
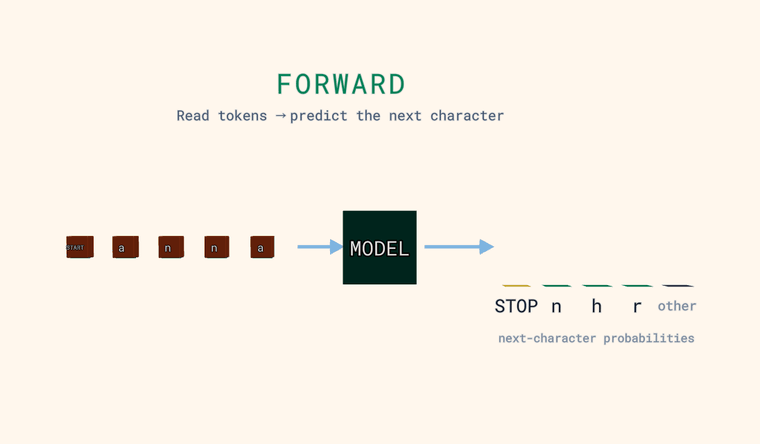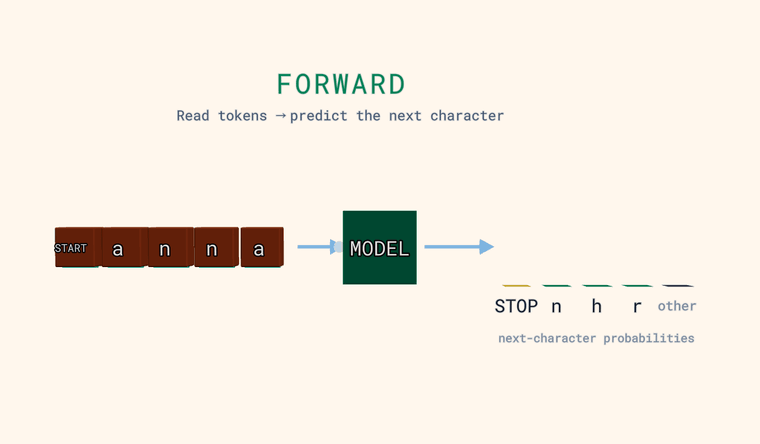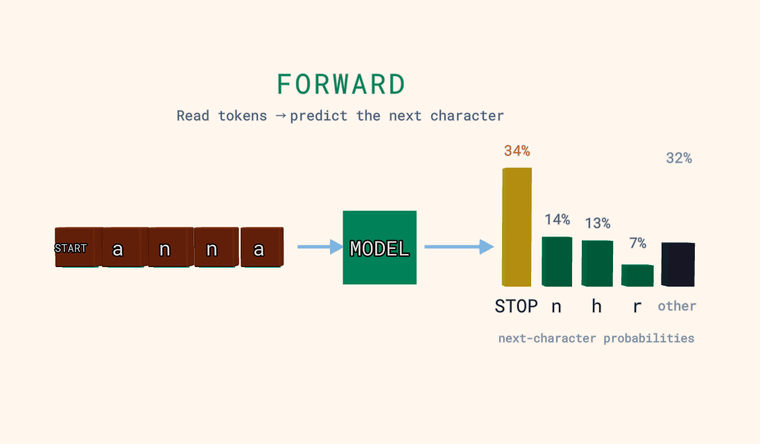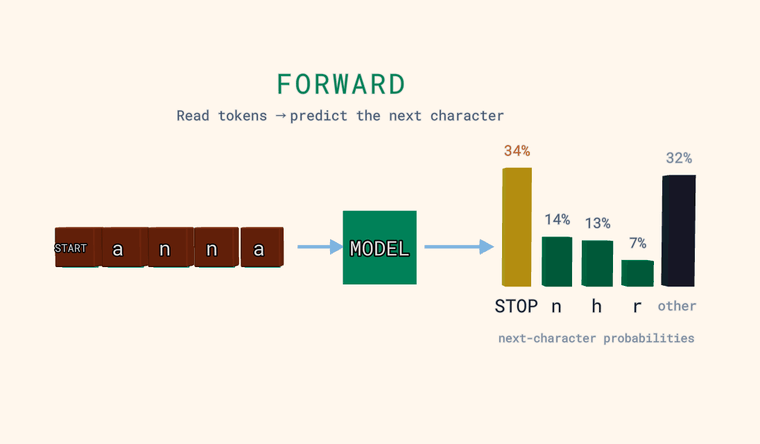
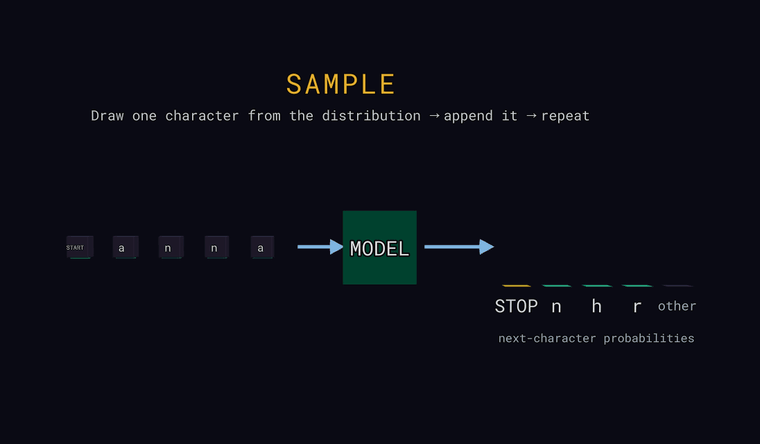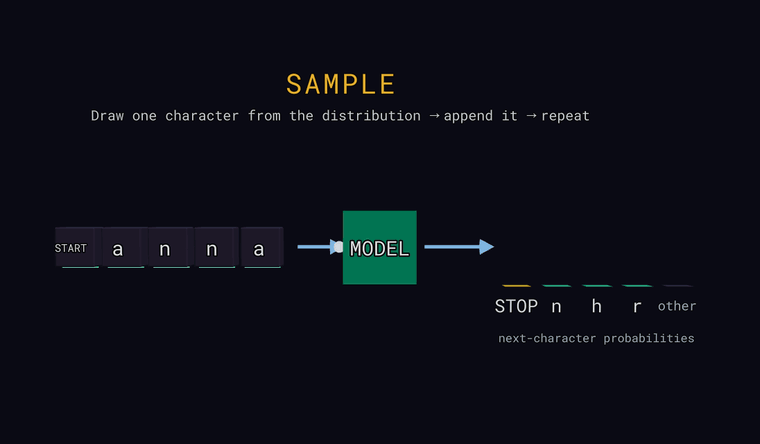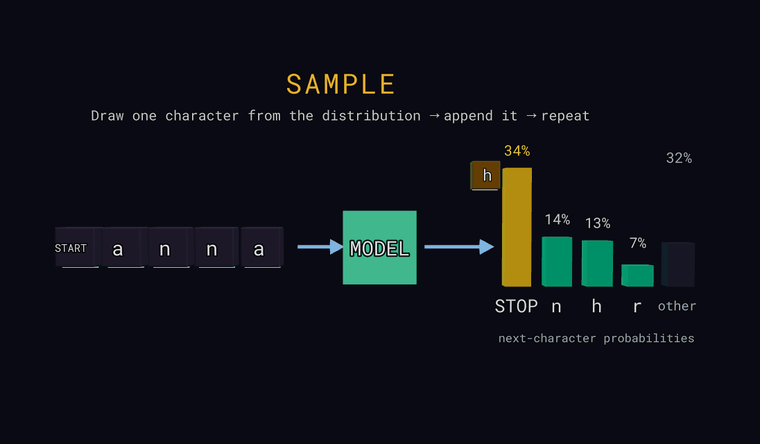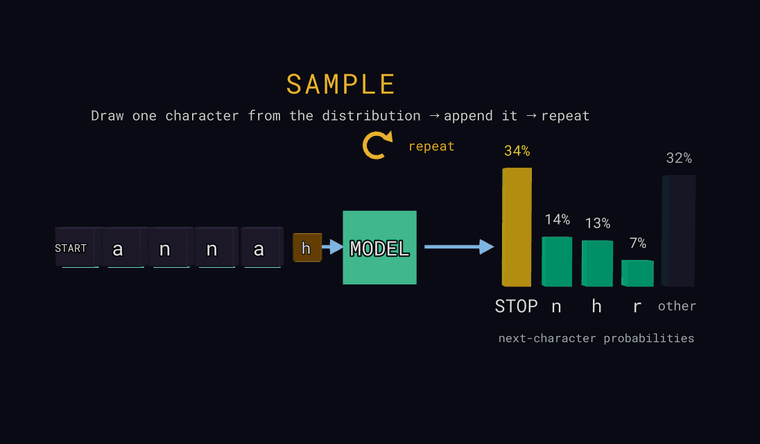
Forward — модель читает символы и предсказывает вероятность для каждого возможного следующего символа. Столбики справа — это и есть распределение: несколько самых вероятных, плюс нейтральный столбик other — суммарная вероятность всех символов, не показанных по отдельности (сумма, а не один кандидат). Один особый токен — это страж: в самом начале входа он означает START, а когда модель предсказывает его как следующий символ — он означает STOP, конец текста. Главное: модель выдаёт распределение, а не один-единственный ответ.
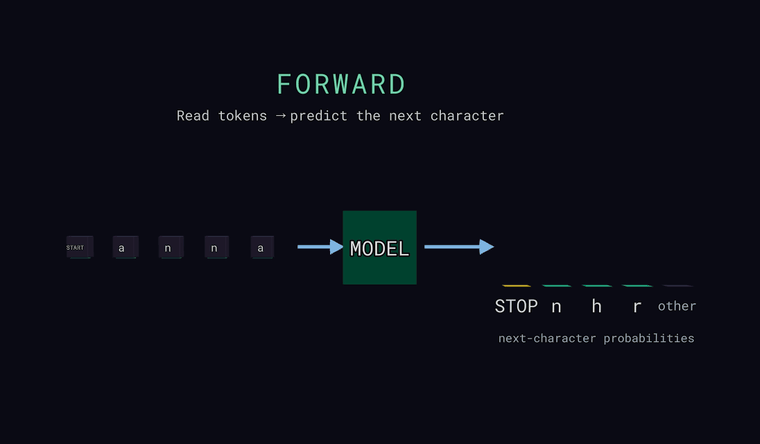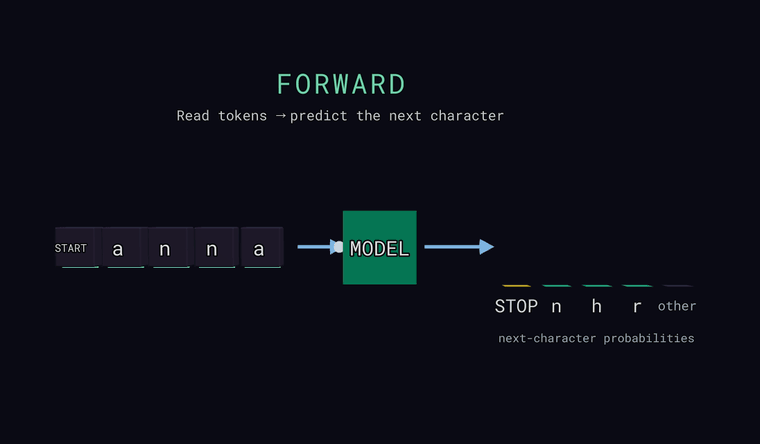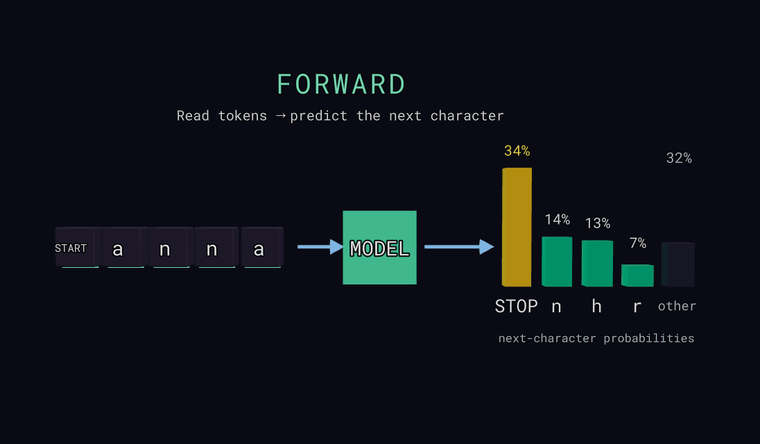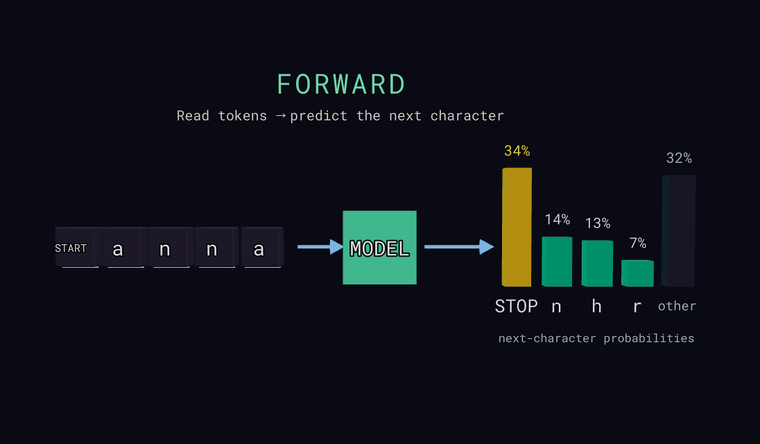
Loss — для каждой позиции модель предсказывает следующий символ, и мы сравниваем это с настоящим следующим символом. Зелёная галочка — её главная ставка совпала, красный крестик — нет. Но сами потери — это минус логарифм вероятности, которую модель дала истине, -log p(true), усреднённый по позициям. То есть потери зависят от вероятности истины, а не только от того, совпала ли главная ставка.


Sample — на последней позиции вытащи один символ случайно, в соответствии с вероятностями (не обязательно самый вероятный), допиши его ко входу и повторяй — так генерируется текст. Если жребий попадает в столбик other, дописывается реальный скрытый за ним символ; если вытянут страж STOP — генерация заканчивается.

Урок 02 приближает камеру к автограду, который делает возможным «учиться на потерях». Урок 03 — к блоку self-attention. А этот остаётся на высоте птичьего полёта.
Аннотированный код
Прямой проход использует три вспомогательные функции — linear, softmax, rmsnorm — и одну большую функцию gpt(), которая их соединяет. Помощники живут в src/microgpt_annotated.py, подраздел overview-pipeline-helpers:
def linear(x, w):
return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]
def softmax(logits):
max_val = max(val.data for val in logits)
exps = [(val - max_val).exp() for val in logits]
total = sum(exps)
return [e / total for e in exps]
def rmsnorm(x):
ms = sum(xi * xi for xi in x) / len(x)
scale = (ms + 1e-5) ** -0.5
return [xi * scale for xi in x]Шаг обучения (подраздел overview-training-step) — это просто: прямой проход → вычислить потери относительно истины → loss.backward() → обновление Adam (с линейным затуханием скорости обучения) для каждого параметра — оптимизатору посвящён урок 05 · Обучение и генерация. Порт на TypeScript в src/inference/{model,value,weights}.ts реализует тот же прямой путь, поэтому эта песочница гоняет его вживую у тебя в браузере, на тех самых ~89 КБ обученных весов, закоммиченных в репозиторий.
Песочница
Набери до 10 символов (или выбери пресет). Переключай режимы: Forward показывает предсказанную вероятность следующего символа; Loss сравнивает каждое предсказание с настоящим следующим символом; Sample вытягивает один символ из распределения последней позиции и дописывает его.
Попробуй сам.
- Набери
annв режиме Forward. Модель видела кучу имён — стоит лиaна первом месте её ставок на следующую букву? Сколько вероятности она отдаётSTOP?- Теперь набери что-нибудь глубоко непохожее на имя, например
xqz. Смотри, как распределение расплющивается: модель говорит тебе «понятия не имею» — числами.- Переключись в режим Loss с настоящим именем. Найди позицию с красным крестиком, где у истины всё же была приличная вероятность — вот она, разница между «главная ставка не сошлась» и «большие потери».
- В режиме Sample пересэмплируй несколько раз с одного и того же префикса. Один вход — разные выходы: это и есть сэмплирование из распределения вместо выбора максимума.